
Loading and Saving Data#
Now that we talked a lot about how to control instruments using Python, let us talk about how to get data in and out of your programs.
Learning Outcomes#
Learn how to:
load and save text files into your programs
load and save
numpyfilesserializing your objects
interact with Matlab (load and save Matlab files)
more advanced text file parsing
how to deal with binary data
advanced file-saving with tables
Modules we will use#
numpy
pickle
struct
tables
Text files in Python#
Let us first review how to read and write text files in “plain” Python (although this is often not what you want)
Python has in-build support for file handling, in particular for dealing with text files. To open a file use the open command.
# lets start by reading from a previously generated text file
fp = open("testreadfile.txt", "r") # this open command opens a file in "read text mode" (the text is implicit) and returns a stream
# it is worthwhile to have a look at the open documentation in particular look at the different modes
help(open)
Help on function open in module io:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Open file and return a stream. Raise OSError upon failure.
file is either a text or byte string giving the name (and the path
if the file isn't in the current working directory) of the file to
be opened or an integer file descriptor of the file to be
wrapped. (If a file descriptor is given, it is closed when the
returned I/O object is closed, unless closefd is set to False.)
mode is an optional string that specifies the mode in which the file
is opened. It defaults to 'r' which means open for reading in text
mode. Other common values are 'w' for writing (truncating the file if
it already exists), 'x' for creating and writing to a new file, and
'a' for appending (which on some Unix systems, means that all writes
append to the end of the file regardless of the current seek position).
In text mode, if encoding is not specified the encoding used is platform
dependent: locale.getpreferredencoding(False) is called to get the
current locale encoding. (For reading and writing raw bytes use binary
mode and leave encoding unspecified.) The available modes are:
========= ===============================================================
Character Meaning
--------- ---------------------------------------------------------------
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
'U' universal newline mode (deprecated)
========= ===============================================================
The default mode is 'rt' (open for reading text). For binary random
access, the mode 'w+b' opens and truncates the file to 0 bytes, while
'r+b' opens the file without truncation. The 'x' mode implies 'w' and
raises an `FileExistsError` if the file already exists.
Python distinguishes between files opened in binary and text modes,
even when the underlying operating system doesn't. Files opened in
binary mode (appending 'b' to the mode argument) return contents as
bytes objects without any decoding. In text mode (the default, or when
't' is appended to the mode argument), the contents of the file are
returned as strings, the bytes having been first decoded using a
platform-dependent encoding or using the specified encoding if given.
'U' mode is deprecated and will raise an exception in future versions
of Python. It has no effect in Python 3. Use newline to control
universal newlines mode.
buffering is an optional integer used to set the buffering policy.
Pass 0 to switch buffering off (only allowed in binary mode), 1 to select
line buffering (only usable in text mode), and an integer > 1 to indicate
the size of a fixed-size chunk buffer. When no buffering argument is
given, the default buffering policy works as follows:
* Binary files are buffered in fixed-size chunks; the size of the buffer
is chosen using a heuristic trying to determine the underlying device's
"block size" and falling back on `io.DEFAULT_BUFFER_SIZE`.
On many systems, the buffer will typically be 4096 or 8192 bytes long.
* "Interactive" text files (files for which isatty() returns True)
use line buffering. Other text files use the policy described above
for binary files.
encoding is the name of the encoding used to decode or encode the
file. This should only be used in text mode. The default encoding is
platform dependent, but any encoding supported by Python can be
passed. See the codecs module for the list of supported encodings.
errors is an optional string that specifies how encoding errors are to
be handled---this argument should not be used in binary mode. Pass
'strict' to raise a ValueError exception if there is an encoding error
(the default of None has the same effect), or pass 'ignore' to ignore
errors. (Note that ignoring encoding errors can lead to data loss.)
See the documentation for codecs.register or run 'help(codecs.Codec)'
for a list of the permitted encoding error strings.
newline controls how universal newlines works (it only applies to text
mode). It can be None, '', '\n', '\r', and '\r\n'. It works as
follows:
* On input, if newline is None, universal newlines mode is
enabled. Lines in the input can end in '\n', '\r', or '\r\n', and
these are translated into '\n' before being returned to the
caller. If it is '', universal newline mode is enabled, but line
endings are returned to the caller untranslated. If it has any of
the other legal values, input lines are only terminated by the given
string, and the line ending is returned to the caller untranslated.
* On output, if newline is None, any '\n' characters written are
translated to the system default line separator, os.linesep. If
newline is '' or '\n', no translation takes place. If newline is any
of the other legal values, any '\n' characters written are translated
to the given string.
If closefd is False, the underlying file descriptor will be kept open
when the file is closed. This does not work when a file name is given
and must be True in that case.
A custom opener can be used by passing a callable as *opener*. The
underlying file descriptor for the file object is then obtained by
calling *opener* with (*file*, *flags*). *opener* must return an open
file descriptor (passing os.open as *opener* results in functionality
similar to passing None).
open() returns a file object whose type depends on the mode, and
through which the standard file operations such as reading and writing
are performed. When open() is used to open a file in a text mode ('w',
'r', 'wt', 'rt', etc.), it returns a TextIOWrapper. When used to open
a file in a binary mode, the returned class varies: in read binary
mode, it returns a BufferedReader; in write binary and append binary
modes, it returns a BufferedWriter, and in read/write mode, it returns
a BufferedRandom.
It is also possible to use a string or bytearray as a file for both
reading and writing. For strings StringIO can be used like a file
opened in a text mode, and for bytes a BytesIO can be used like a file
opened in a binary mode.
So what do we do with the stream objects?
help(fp)
Help on TextIOWrapper object:
class TextIOWrapper(_TextIOBase)
| TextIOWrapper(buffer, encoding=None, errors=None, newline=None, line_buffering=False, write_through=False)
|
| Character and line based layer over a BufferedIOBase object, buffer.
|
| encoding gives the name of the encoding that the stream will be
| decoded or encoded with. It defaults to locale.getpreferredencoding(False).
|
| errors determines the strictness of encoding and decoding (see
| help(codecs.Codec) or the documentation for codecs.register) and
| defaults to "strict".
|
| newline controls how line endings are handled. It can be None, '',
| '\n', '\r', and '\r\n'. It works as follows:
|
| * On input, if newline is None, universal newlines mode is
| enabled. Lines in the input can end in '\n', '\r', or '\r\n', and
| these are translated into '\n' before being returned to the
| caller. If it is '', universal newline mode is enabled, but line
| endings are returned to the caller untranslated. If it has any of
| the other legal values, input lines are only terminated by the given
| string, and the line ending is returned to the caller untranslated.
|
| * On output, if newline is None, any '\n' characters written are
| translated to the system default line separator, os.linesep. If
| newline is '' or '\n', no translation takes place. If newline is any
| of the other legal values, any '\n' characters written are translated
| to the given string.
|
| If line_buffering is True, a call to flush is implied when a call to
| write contains a newline character.
|
| Method resolution order:
| TextIOWrapper
| _TextIOBase
| _IOBase
| builtins.object
|
| Methods defined here:
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __next__(self, /)
| Implement next(self).
|
| __repr__(self, /)
| Return repr(self).
|
| close(self, /)
| Flush and close the IO object.
|
| This method has no effect if the file is already closed.
|
| detach(self, /)
| Separate the underlying buffer from the TextIOBase and return it.
|
| After the underlying buffer has been detached, the TextIO is in an
| unusable state.
|
| fileno(self, /)
| Returns underlying file descriptor if one exists.
|
| OSError is raised if the IO object does not use a file descriptor.
|
| flush(self, /)
| Flush write buffers, if applicable.
|
| This is not implemented for read-only and non-blocking streams.
|
| isatty(self, /)
| Return whether this is an 'interactive' stream.
|
| Return False if it can't be determined.
|
| read(self, size=-1, /)
| Read at most n characters from stream.
|
| Read from underlying buffer until we have n characters or we hit EOF.
| If n is negative or omitted, read until EOF.
|
| readable(self, /)
| Return whether object was opened for reading.
|
| If False, read() will raise OSError.
|
| readline(self, size=-1, /)
| Read until newline or EOF.
|
| Returns an empty string if EOF is hit immediately.
|
| reconfigure(self, /, *, encoding=None, errors=None, newline=None, line_buffering=None, write_through=None)
| Reconfigure the text stream with new parameters.
|
| This also does an implicit stream flush.
|
| seek(self, cookie, whence=0, /)
| Change stream position.
|
| Change the stream position to the given byte offset. The offset is
| interpreted relative to the position indicated by whence. Values
| for whence are:
|
| * 0 -- start of stream (the default); offset should be zero or positive
| * 1 -- current stream position; offset may be negative
| * 2 -- end of stream; offset is usually negative
|
| Return the new absolute position.
|
| seekable(self, /)
| Return whether object supports random access.
|
| If False, seek(), tell() and truncate() will raise OSError.
| This method may need to do a test seek().
|
| tell(self, /)
| Return current stream position.
|
| truncate(self, pos=None, /)
| Truncate file to size bytes.
|
| File pointer is left unchanged. Size defaults to the current IO
| position as reported by tell(). Returns the new size.
|
| writable(self, /)
| Return whether object was opened for writing.
|
| If False, write() will raise OSError.
|
| write(self, text, /)
| Write string to stream.
| Returns the number of characters written (which is always equal to
| the length of the string).
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| buffer
|
| closed
|
| encoding
| Encoding of the text stream.
|
| Subclasses should override.
|
| errors
| The error setting of the decoder or encoder.
|
| Subclasses should override.
|
| line_buffering
|
| name
|
| newlines
| Line endings translated so far.
|
| Only line endings translated during reading are considered.
|
| Subclasses should override.
|
| write_through
|
| ----------------------------------------------------------------------
| Methods inherited from _IOBase:
|
| __del__(...)
|
| __enter__(...)
|
| __exit__(...)
|
| __iter__(self, /)
| Implement iter(self).
|
| readlines(self, hint=-1, /)
| Return a list of lines from the stream.
|
| hint can be specified to control the number of lines read: no more
| lines will be read if the total size (in bytes/characters) of all
| lines so far exceeds hint.
|
| writelines(self, lines, /)
| Write a list of lines to stream.
|
| Line separators are not added, so it is usual for each of the
| lines provided to have a line separator at the end.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from _IOBase:
|
| __dict__
# read a single line of the file
l1 = fp.readline()
print(l1)
Etiam vel tortor sodales tellus ultricies commodo.
# read another line
l2 = fp.readline()
print(l2)
* Nunc aliquet, augue nec adipiscing interdum, lacus tellus malesuada massa, quis varius mi purus non odio.
# read a single character
c1 = fp.read(1)
print(c1)
F
# what happens if we read the line now?
l3 = fp.readline()
print(l3)
usce suscipit, wisi nec facilisis facilisis, est dui fermentum leo, quis tempor ligula erat quis odio. Nunc porta vulputate tellus. Nunc rutrum turpis sed pede. Sed bibendum. Aliquam posuere. Nunc aliquet, augue nec adipiscing interdum, lacus tellus malesuada massa, quis varius mi purus non odio. Pellentesque condimentum, magna ut suscipit hendrerit, ipsum augue ornare nulla, non luctus diam neque sit amet urna. Curabitur vulputate vestibulum lorem. Fusce sagittis, libero non molestie mollis, magna orci ultrices dolor, at vulputate neque nulla lacinia eros. Sed id ligula quis est convallis tempor.
# let's put the line back together
l3 = c1+l3
print(l3)
Fusce suscipit, wisi nec facilisis facilisis, est dui fermentum leo, quis tempor ligula erat quis odio. Nunc porta vulputate tellus. Nunc rutrum turpis sed pede. Sed bibendum. Aliquam posuere. Nunc aliquet, augue nec adipiscing interdum, lacus tellus malesuada massa, quis varius mi purus non odio. Pellentesque condimentum, magna ut suscipit hendrerit, ipsum augue ornare nulla, non luctus diam neque sit amet urna. Curabitur vulputate vestibulum lorem. Fusce sagittis, libero non molestie mollis, magna orci ultrices dolor, at vulputate neque nulla lacinia eros. Sed id ligula quis est convallis tempor.
# read to the end
s2 = fp.read()
print(s2)
Curabitur lacinia pulvinar nibh. Nam a sapien.
# lets move back to the beginning
fp.seek(0)
0
# read text as lines
fp.readlines()
['Etiam vel tortor sodales tellus ultricies commodo. \n',
'* Nunc aliquet, augue nec adipiscing interdum, lacus tellus malesuada massa, quis varius mi purus non odio.\n',
'Fusce suscipit, wisi nec facilisis facilisis, est dui fermentum leo, quis tempor ligula erat quis odio. Nunc porta vulputate tellus. Nunc rutrum turpis sed pede. Sed bibendum. Aliquam posuere. Nunc aliquet, augue nec adipiscing interdum, lacus tellus malesuada massa, quis varius mi purus non odio. Pellentesque condimentum, magna ut suscipit hendrerit, ipsum augue ornare nulla, non luctus diam neque sit amet urna. Curabitur vulputate vestibulum lorem. Fusce sagittis, libero non molestie mollis, magna orci ultrices dolor, at vulputate neque nulla lacinia eros. Sed id ligula quis est convallis tempor. \n',
'Curabitur lacinia pulvinar nibh. Nam a sapien.\n',
'\n',
'\n',
'\n']
# close the file
fp.close()
Saving to Text file with Python#
The operations for saving to a text file are very similar to how to read from files
fp = open("testwritefile.txt", "w")
fp.write("Test text")
fp.write("more text") # this will be concatenated just after the other text
fp.write("start a new line after this\n") # to start a new line put a end of line character
fp.writelines(["line1", "line2", "line3"]) # careful this name is confusing! it does not add newline characters!
fp.close() # IMPORTANT the data does get buffered (see the documentation) so will only fully be written when closing the object
Files in Numpy#
While the plain Python methods are very powerful, they can be also very cumbersome to use. In particular saving numerical data to text files
Advantages#
can be opened pretty much everywhere
Disadvantages#
file size is large (compared to binary data)
slow saving
slow loading
formatting when writing
can lead to precision loss
slower
cumbersome to read and write files
need to convert to numerical values
delimiters
comments
Saving numpy arrays#
Numpy offers some basic file-handling capabilities for saving and writing numpy arrays.
import numpy as np
# generate a random array to save
a = np.random.randn(10**5)
# save the single array
np.save("testarray", a) # note that numpy automatically adds the "npy" extension
# loading works the same way
a2 = np.load("testarray.npy") #for loading we need to add the extension
np.all(a2==a) # note that comparing 2 floating point arrays with equality is not guaranteed to return True
True
# saving also preserves the shape
np.save("testarray2", a.reshape(10,10**4))
a3 = np.load("testarray2.npy")
a3.shape == (10, 10**4) # for integers we can use it
True
Saving more than a single file is slightly more involved. There is no equivalent to matlab save.
np.savez("twoarrays", array1=a, array2=a3) # if you want compression use np.savez_compressed
d = np.load("twoarrays.npz") # note the file extension. Essentially NPZ files are multiple npy files zipped together (uncompressed)
d.files
['array1', 'array2']
a_new = d['array1']
a3_new = d['array2']
print(np.allclose(a_new,a)) # np.allclose is better than comparing for equality
print(np.all(a3_new.shape==a3.shape))
True
True
When to use?#
need only Python (numpy) interoperability
written data fits in memory
do not need to extend
need to save numpy arrays
Numpy and text files#
Because it is so common to work with data in row/column text files (or csv files), numpy has some powerful functions for loading and saving data in these formats. The two functions are np.loadtxt and np.savetxt
x = np.arange(10).reshape(5, 2) # 5 rows 2 columns
np.savetxt("columndata.txt", x)
x2 = np.loadtxt("columndata.txt")
np.allclose(x2,x)
True
The great thing about this is that it has a lot of parsing build in. Here’s an old trace saved from an OSA.
fp = open("osadata.txt")
content = fp.read(370)
fp.close()
print(content)
File,DATA272.txt
Date/Time,07-01-12/13:57
Center,1570.0,nm
Span,260.0,nm
Start,1440.0,nm
Stop,1700.0,nm
Value in Vacuum
Resolution,0.07,nm
Act-Res,0.06,nm
VBW,1000,Hz
Average,Off
Smooth,Off
Smplg,1001,pt
Opt.ATT,Off
Dynamic Range,Normal
Normal
Trace,A
Memory,A
Start,1440.0,nm
Stop,1700.0,nm
1440.0,0.5835E-5,1.0000E-12
1440.26,0.9913E-
%pylab inline
# reading with numpy loadtxt
wl, s1, s2 = np.loadtxt("osadata.txt", skiprows=24, delimiter=",", unpack=True) #unpack returns the different columns as separate arrays
plt.semilogy(wl, s1)
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
[<matplotlib.lines.Line2D at 0x783c6c5808e0>]
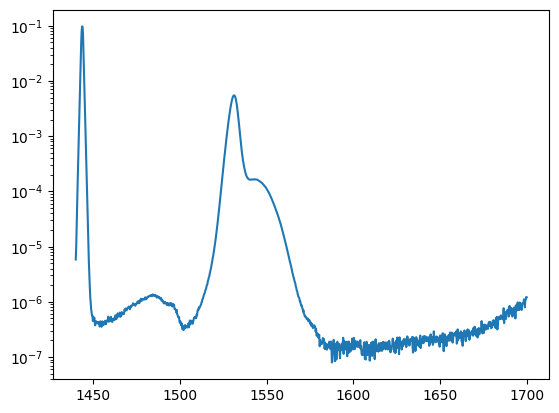
Much more powerful conversions are possible please read the documentation
When to use loadtxt/savetxt#
np.loadtxt:
everytime you need to load numerical data in text format
always try loadtxt first (much easier than manual parsing)
np.savetxt:
avoid with large amounts of data
use when you want the best interoperability (e.g. load into Excel, but why would you after learning python 😀)
Interacting with Matlab#
A lot of people are moving to Python from Matlab or are working with colleagues who use Matlab. Unfortunately numpy does not allow reading from and writing to Matlab files. Fortunately scipy does.
from scipy.io import loadmat, savemat
mfile = loadmat("chicom.mat")
print(mfile)
{'__header__': b'MATLAB 5.0 MAT-file, Platform: ALPHA, Created on: Fri Feb 4 11:49:16 2000', '__version__': '1.0', '__globals__': [], 'fTHz': array([[-30. , -29.95, -29.9 , ..., 29.9 , 29.95, 30. ]]), 'chi1111': array([[-0.25776039-0.05188768j, -0.26075023-0.05231145j,
-0.26378004-0.05281668j, ..., -0.26378004+0.05281668j,
-0.26075023+0.05231145j, -0.25776039+0.05188768j]])}
f = mfile["fTHz"].flatten() # matlab saves as 2-d files even if only 1D
chi = mfile["chi1111"].flatten()
fg,ax = plt.subplots(1,2, figsize=(16, 6))
ax[0].plot(f, chi.real)
ax[1].plot(f, chi.imag)
[<matplotlib.lines.Line2D at 0x783c608b5c60>]
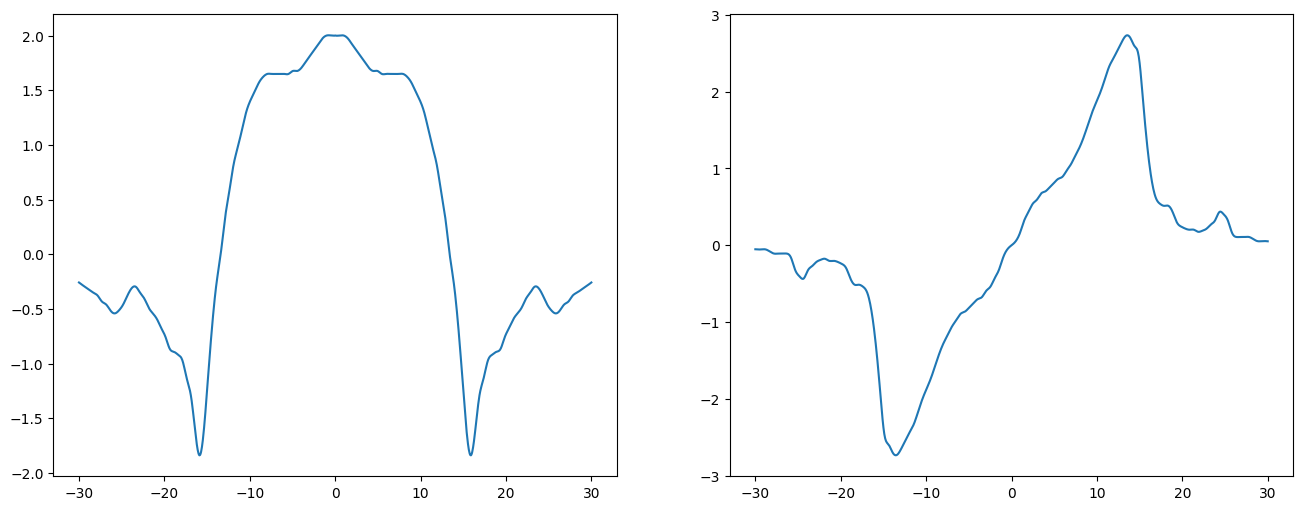
How to save Python objects#
Sometimes we do not just want to save numerical data or arrays, but Python objects. When we later read the file we want to have those objects back.
One could write a function to save the object by separating into several e.g. numpy arrays and save using np.savez. To load we would then write another function that would write another function to generate the object back from a np.loaded file.
This is failure-prone
We need to remember the format we saved in
Changes to the object need to be reflected in the save function
How to load old files (after the object changed)
From wikipedia:
serialization (or serialization) is the process of translating data structures or object state into a format that can be stored (for example, in a file or memory buffer) or transmitted (for example, across a network connection link) and reconstructed later (possibly in a different computer environment)
Python provides a powerful serialization package called pickle which enables this.
# crate some class
class Rect(object):
def __init__(self, x,y):
self.x = x
self.y = y
def cal_area(self):
return self.x*self.y
x = Rect(5, 7.)
import pickle
fp = open("testpickle.pic", "wb") # note the 'b' which means we are saving in byte format
pickle.dump(x, fp)
fp.close()
fp = open("testpickle.pic", "rb")
xnew = pickle.load(fp)
fp.close()
print(xnew)
print(type(xnew))
print(xnew.x)
print(xnew.y)
print(xnew.cal_area())
<__main__.Rect object at 0x783c78576890>
<class '__main__.Rect'>
5
7.0
35.0
Important points when using pickle#
Not all objects are picklable (see the documentation for what is and isn’t)
highly recursive structures can be difficult and/or slow
you can customize the “picklability” of your classes
Not space efficient (compress)
can be slow (use different protocols)